I sistemi a supporto del customer management, possono beneficiare delle opportunità offerte da un terreno complessivamente più fertile in termini di disponibilità dei dati, aumentate efficienze informatiche, accresciute capacità analytics, puntando da subito sul patrimonio informativo più rilevante e differenziante, nonché di focalizzarsi sugli aspetti prioritari per accrescere la fidelizzazione del cliente e la capacità di retention
Luciano Bruccola, Conectens
Pubblicato su APBNews n.1 2014
Studi e ricerche condotte recentemente dalle società di consulenza internazionali al fine di individuare i trend e le priorità nel mondo dei servizi finanziari si focalizzano su due aspetti interdipendenti e connessi alle dinamiche di comportamento dei clienti e alla necessità di intercettare tali dinamiche per una comprensione delle stesse e per indirizzare opportunamente le politiche e le azioni di relazione cliente.
Le strategie e le priorità identificate dalle banche e dagli istituti finanziari di fronte al rallentamento economico complessivo rilevano il focus sul cliente – la capacità di attrarre, di fidelizzare e di sviluppo commerciale aggiuntivo – come elemento centrale della strategia da porre in essere per attenuarne l’impatto. L’appannamento della fiducia verso le banche comporta una diminuzione del grado di fidelizzazione ed una spinta a fenomeni di multibancarizzazione e l’accresciuta presenza del web (sia come disponibilità delle informazioni, sia come condivisione di customer experiences), congiunta ad una maggiore presa di coscienza dei clienti, impone una attenzione maggiore nel cogliere gli insights necessari a gestire i propri clienti [i], anche in ottica di diversificazione dei canali per aumentare fidelizzazione e capacità di retention [ii].
L’altro grande elemento presente nel dibattito internazionale, di interesse in questo contesto, è quello generalmente chiamato Big Data e che fa riferimento alla possibilità di accesso a nuovi dati – resi disponibili dal processo tecnologico – per aumentare la capacità di comprensione dei propri clienti. Grazie soprattutto alle tecnologie digitali, le aziende e le organizzazioni raccolgono un volume crescente di informazioni transazionali sui clienti, sui fornitori, sui servizi e generano un immenso ammontare di dati digitali come parte dei processi, il cui potere informativo non è ancora utilizzato pienamente. Basti pensare ai social media, agli smartphone e ai pc che consentono agli utilizzatori di generare una mole impressionante di dati, oppure agli strumenti come i telefoni cellulari, le automobili, i rilevatori di consumo energetico che creano e comunicano dati in modo automatico. La disponibilità dei dati associata a spinte capacità analitiche impatta tra le altre cose una maggiore facilità di condurre sperimentazioni, la possibilità di realizzare segmentazioni ancora più fini e specifiche per identificare prodotti e servizi che incontrano i bisogni dei clienti, l’innovazione di nuovi prodotti e servizi, migliorando i modelli di business esistenti ovvero inventandone di nuovi[iii].
In sintesi da un lato la situazione economica complessiva enfatizza ancor di più la centralità del cliente, dall’altro la ricerca e la potenziale disponibilità di fonti informative innovative, le accresciute capacità informatiche di gestione di moli di dati, la maggiore facilità di utilizzo delle capacità Analytics per tradurre queste in elementi sui quali fondare strategie e azioni operative enfatizza l’approccio data driven al customer management che consente di utilizzare ancor più il contenuto informativo disponibile.
Obiettivo di questo articolo è di riprendere in esame i concetti base di un approccio alla relazione cliente nei servizi finanziari guidato dai dati e dalle informazioni disponibili e esaminare quanto questo sia coerente e funzionale al momento e ai temi di Customer Retention e Big Data qui brevemente descritti.
Le informazioni disponibili sui clienti
L’obiettivo della raccolta di dati e informazioni sul cliente è di coglierne quanto più possibile la complessità rispetto ai temi di interesse per la propria offerta (esempio per i clienti privati: attitudini a risparmio ed al consumo, maturità finanziaria e prodotti di investimento, utilizzo crediti, carte, servizi, canali) secondo il paradigma che quanto più si conosce del cliente tanto più si è in grado di offrire prodotti e servizi che incontrino il suo favore.
La fonte primaria dei dati cui fare riferimento nelle analisi sui clienti e, in particolare sul modo in cui questi approcciano i prodotti e servizi che una banca o una società finanziaria distribuisce, è l’insieme dei dati interni alla organizzazione e raccolti generalmente per fini amministrativi e contabili.
L’importanza dei dati interni varia da settore a settore a seconda del livello di engagement del cliente con l’istituto finanziario, che è condizionato in primis dal ventaglio dei prodotti distribuiti dalla banca o dalla società finanziaria, dalla frequenza di relazione tra il cliente e l’istituto e dal livello di fidelizzazione del cliente stesso.
La complessità catturata dai dati interni della banca sui propri clienti è generalmente elevata perché misurata su diversi prodotti (risparmio, investimento, credito, servizi pagamento), dalla frequenza di relazione (numero elevato di contatti annuali) e dal mix di canali utilizzati (gestore, dipendenza, telefono, web). La complessità catturata dai dati interni di una società finanziaria specializzata che distribuisce credito ai propri clienti è meno elevata perché misurata su 1 o 2 prodotti (esempio: prestito e carta revolving per i privati, leasing e factoring per le aziende) e caratterizzata da una frequenza di relazione contenuta (più elevata comunque per le carte revolving). Il ricorso a dati esterni è tanto più importante quanto più si ha una relazione debole con il cliente (livello di engagement e fidelizzazione basso) e quanto meno frequenti sono le occasioni di contatto. Nel caso poi di sviluppo commerciale su liste esterne i dati generalmente disponibili non consentono di catturare un livello soddisfacente di complessità e il ricorso a dati e strumenti esterni è ancora più necessario.
Una volta raccolto il patrimonio informativo disponibile è necessaria un’analisi attenta dello stesso che consenta di misurarne la copertura e la qualità dei dati, nonché il contenuto e valore informativo apportato. D’altro canto più dati si raccolgono più diventa pressante costruire delle opportune visioni di sintesi che consentano di utilizzare operativamente le informazioni.
La ricchezza del patrimonio disponibile condiziona e modula sia gli indicatori di sintesi che si possono costruire sui dati e ancor più l’utilizzo operativo che se ne può fare. In sintesi se il patrimonio informativo interno è rilevante (nel caso delle banche) i modelli di classificazione sono costruiti sulla base dei dati interni disponibili, hanno per obiettivo la classificazione e segmentazione della base clienti per comportamento, per propensity ai diversi prodotti, per il grado di retention, per il livello di credit risk e sono utilizzati per le azioni di customer management, per le campagne di cross/up selling, per la prevenzione dell’attrition e per il credit risk management.
Figura 1
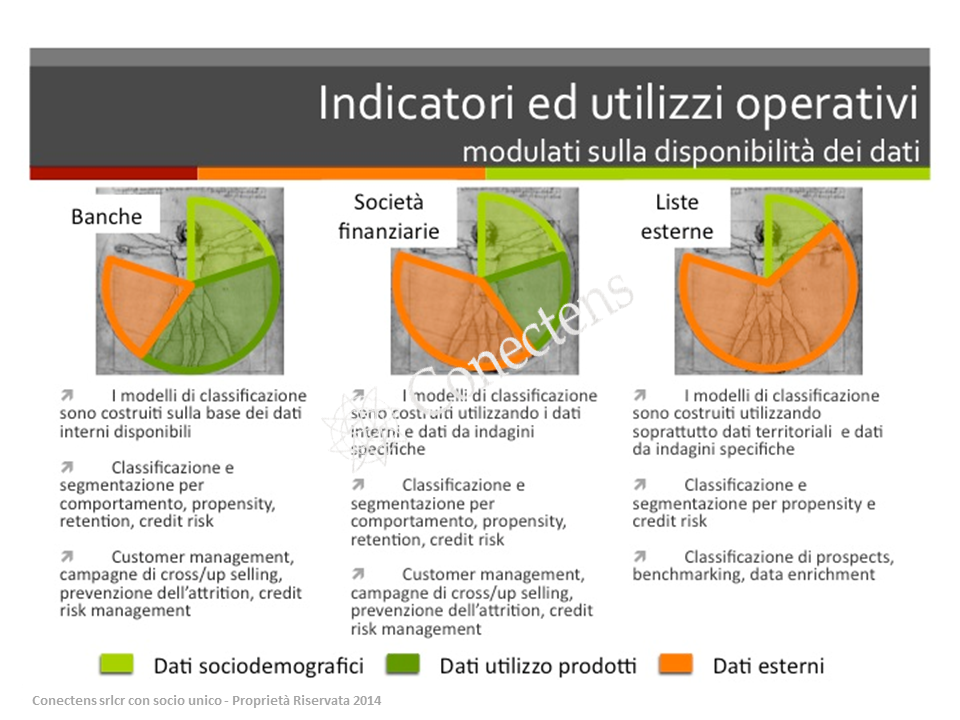
Nel caso invece di un patrimonio interno di informazioni non soddisfacentemente ampio da coprire una porzione importante di “complessità” da gestire (nel caso delle società finanziarie) i modelli di classificazione sono costruiti utilizzando i dati interni e dati provenienti da indagini specifiche sui propri clienti che consentano di colmare tale gap informativo. Se questo è possibile allora sia gli indicatori di sintesi sia gli utilizzi operativi sono paragonabili al caso delle banche.
Infine, nel caso di scarso contenuto informativo dei dati interni disponibili è necessario raccogliere dall’esterno informazioni che condizionano anche la possibilità di utilizzo operativo delle stesse. In particolare i modelli di classificazione sono costruiti utilizzando soprattutto dati territoriali e dati da indagini specifiche, la classificazione e la segmentazione dei clienti è volta ad inquadrare la propensity per un dato prodotto e – nel caso di prodotti di credito – ad inquadrare il livello di rischio connesso per un primo prescreening, gli utilizzi operativi sono volti quindi a classificare prospects.
Gli approcci al customer profiling
La classificazione della clientela (customer profiling) trova il presupposto nell’avere a disposizione modelli interpretativi che facilitino la rappresentazione della complessità della clientela e che, quindi, guidino l’individuazione dell’approccio commerciale (offerta) e di relazione (canale e marketing) più consono per ciascuna tipologia di cliente, o meglio di gruppo di clienti. Ciascun cliente viene quindi assegnato ad uno specifico gruppo per la individuazione dei quali, ci si affida ad uno o più elementi presenti nella base ovvero reperiti all’esterno.
Si possono distinguere 3 grandi famiglie di approccio al customer profiling: l’utilizzo di una o più variabili/informazioni di base, la sintesi di più variabili per prevedere particolari eventi (scoring) ovvero per definire cluster diversi (segmentazioni), l’utilizzo di segmentazioni esterne riconducibili al singolo cliente.
L’utilizzo di una o più informazioni di base
Nel primo approccio ricoprono un ruolo fondamentale le variabili socio demografiche a disposizione: le segmentazioni per età e per professione hanno rappresentato il primo step (semplice da realizzare e semplice da comunicare ed utilizzare) che ha guidato i processi di costituzione di prodotti/offerta per segmenti specifici. Una caratteristica importante di questi modelli, che deriva appunto dalla semplicità di costruzione, è che si possono facilmente applicare ai clienti e ai non-clienti grazie alla compilazione immediata del formulario anagrafico che raccoglie le informazioni necessarie alla classificazione nel segmento di età e/o di professione corrispondente. È quindi possibile indirizzare, sin da subito, l’offerta studiata per il segmento specifico. Un’altra applicazione importante della segmentazione ad una sola variabile è la cosiddetta segmentazione patrimoniale secondo cui si classifica un cliente per l’ammontare della raccolta che ha presso la banca in esame sommando il saldo sul c/c, il saldo sui libretti e depositi di risparmio, il saldo sul conto titoli. Fondamentalmente si riconoscono tre macro segmenti di clientela: i clienti Private, gli Affluent, i Mass. Il salto concettuale è evidente: la classificazione è guidata dal livello di relazione che il cliente ha con la specifica banca e non dalle caratteristiche complessive del cliente stesso. In altre parole esistono (e non sono pochi) clienti di più banche che possono essere Private per una data banca e Mass per un’altra. I pro dell’approccio risiedono nella semplicità di calcolo e di assegnazione al segmento, nella univocità d’interpretazione (non c’è soggettività), nella semplicità di confronti con altre realtà. È il modello di segmentazione che – a partire dagli anni 90 – ha guidato e guida il riconoscimento dei clienti importanti e la costituzione di portafogli di clienti da gestire in modo diretto e non attraverso la classica rete di filiali.
La sintesi di più variabili
Nei modelli di scoring le informazioni disponibili vengono sintetizzate in una unica variabile per predire un dato evento/comportamento (tipicamente acquisto di un dato prodotto, utilizzo di un dato canale distributivo e, nel mondo credit risk, rispetto delle regole di rimborso). È il frutto della applicazione di un modello statistico, in cui la variabile risposta (dicotomica: acquisto non acquisto di un determinato prodotto) è messa in relazione con l’insieme delle informazioni disponibili al momento in cui si è effettuata l’azione. Per la costruzione di questo modelli è necessario quindi avere delle esperienze di azioni commerciali passate per le quali sia possibile costruire l’esercizio di collegare le informazioni disponibili al momento di messa in opera della azione con le successive risposte ottenute: proposta di acquisto di un prodotto e reazione del cliente (acquisto, non acquisto). A completamento dell’esercizio è possibile assegnare a priori a ciascun cliente la probabilità di acquisto di un determinato prodotto. Sinteticamente si può rappresentare nel seguente modo: Prob acquisto prodotto A = f (x1, …, xn); ove la variabile dipendente è una variabile che assume valori 0 (non acquisito prodotto A) ovvero 1 (acquisito prodotto A), x1, …, xn rappresentano le informazioni disponibili al momento in cui è stata lanciata la campagna.
Negli approcci di segmentazione, l’obiettivo non è quello di individuare il target per uno specifico prodotto ma quello di classificare i clienti in gruppi dal comportamento e dalle attese omogenei per i quali mettere a punto una offerta (prodotti, canali, comunicazione) specifica. Nella realizzazione di modelli di segmentazione comportamentale, le informazioni interne a disposizione sui clienti vengono utilizzate cercando di sfruttarne al massimo il contenuto informativo e prendendo in considerazione tutte le dimensioni del rapporto cliente-banca. Le variabili di segmentazione non sono soggettivamente predefinite, ma sono costruite attraverso tecniche di analisi multivariata tese a sintetizzare il potere informativo delle variabili di base.
I modelli esterni
I modelli di segmentazione di mercato sono basati su interviste ovvero su rilevazioni dirette di atteggiamenti, di bisogni e di attese, rispetto ai prodotti finanziari su un campione rappresentativo della particolare realtà che si vuole analizzare. L’utilizzo di tecniche statistiche, generalmente di analisi multivariata e di cluster, consente di identificare e quantificare i diversi segmenti, che hanno uno specifico approccio alla offerta di prodotti e servizi oggetto dell’indagine. Di fatto quest’approccio descrive bene le caratteristiche complessive di mercato e le tendenze, consentendo anche di misurare il grado di competizione tra le diverse aziende. Gli evidenti benefici possono essere così sintetizzati: possibilità di scegliere i temi d’interesse attraverso la costruzione di interviste ad hoc, possibilità di raccogliere non solo fatti ma anche atteggiamenti, opinioni e dichiarazioni di comportamento, possibilità di avere un quadro del mercato non alterato dalla particolare relazione del cliente con l’azienda specifica. A dispetto dei benefici sopraelencati esistono dei limiti che possono essere ricondotti alla necessità di contenere il numero delle interviste a causa soprattutto di ragioni di costo e alla impossibilità (o meglio la grande difficoltà) a assegnare ciascun cliente della propria base clienti a ciascuno dei segmenti individuati attraverso l’indagine (venendo meno la disponibilità delle informazioni strettamente necessarie per l’assegnazione al dato segmento).
La segmentazione geodemografica ha l’obiettivo di studiare e di classificare i consumatori attraverso le caratteristiche del territorio in cui questi vivono. L’unità statistica di riferimento è quindi rappresentata da celle o zone territoriali per le quali sono disponibili dati sulla composizione demografica, sociale ed economica delle persone residenti. Lo studio e la classificazione di queste zone territoriali, permette di connotare l’insieme delle persone che vivono in ciascuna zona attraverso un indicatore che ne sintetizza appunto il profilo sociale, economico e culturale. I censimenti della popolazione rappresentano generalmente, nei vari paesi in cui questo approccio è stato sviluppato, sia la fonte delle delimitazioni delle partizioni territoriali (che arrivano ad essere qualche centinaia di migliaia) sia la base informativa prioritaria sulla quale costruire i modelli. Nelle realizzazioni più avanzate le informazioni di base sono arricchite attraverso indagini esterne ovvero incrociando altre fonti informative. Una volta realizzati i modelli si assegna ciascun cliente sulla base del proprio indirizzo di residenza. I punti di forza di quest’approccio possono essere così sintetizzati: disponibilità di un unico modello di segmentazione applicabile sia ai clienti che ai non clienti, possibilità di condurre facilmente degli esercizi di benchmarking, semplicità di implementazione. È evidente che il grado di efficacia di questi modelli dipende strettamente dalla quantità e dalla qualità, in sintesi dalla ricchezza, delle informazioni sulle quali sono costruiti.
La domanda su quale sia l’indicatore che meglio rappresenta la complessità del cliente non può trovare una riposta univoca: come brevemente accennato ogni indicatore ha i propri punti di forza e i propri punti di debolezza e va usato soppesandone, evidentemente, pregi e difetti nel quadro dell’azione o della strategia da porre in essere. Solo a titolo di esempio e senza velleità di essere esaustivo:
- se si vuole inquadrare l’approccio complessivo di un cliente storico ai prodotti e servizi distribuiti si farà riferimento alla segmentazione comportamentale,
- al contrario se si vuole capire la potenzialità di un cliente appena acquisito o da acquisire i modelli di segmentazione geodemografica possono essere il migliore strumento,
- se si vuole pianificare una campagna di cross selling su un prodotto specifico esistente lo scoring di propensity potrà essere il migliore strumento a disposizione,
- se si vuole fare un prescreening dei clienti per un approccio wealth management la valutazione del patrimonio è forse lo strumento più adatto.
Meglio ancora un utilizzo combinato dei diversi indicatori, può produrre una migliore definizione del target a cui puntare superando i limiti di ogni singolo elemento.
Test, learn and store
Da questa sommaria analisi risulta chiaro che per rendere operativo un approccio di tipo data-driven al customer relationship management gli elementi che risultano fondamentali sono la qualificazione di ciascun data asset disponibile che è esercizio fondamentale per comprenderne l’impatto di utilizzo e opportune metodologie di sintesi che consentano di esplodere il contenuto informativo dei dati.
Il terzo aspetto che consente di fare il salto di qualità nell’utilizzo di un così imponente sistema informativo realizzato risiede in quell’insieme di strumenti che consente di progettare, testare, implementare e monitorare le strategie e le azioni di customer relationship management.
E’ attraverso gli esercizi di test&learn che – rispetto ad una data azione obiettivo come la proposta di un prodotto avvero una azione di retention – si misura il grado di efficacia delle basi dati disponibili, dei particolari indicatori di sintesi prescelti per segmentare il target di riferimento e per modulare l’azione di contatto (in termini di contenuti, di comunicazione, di canale).
Figura 2
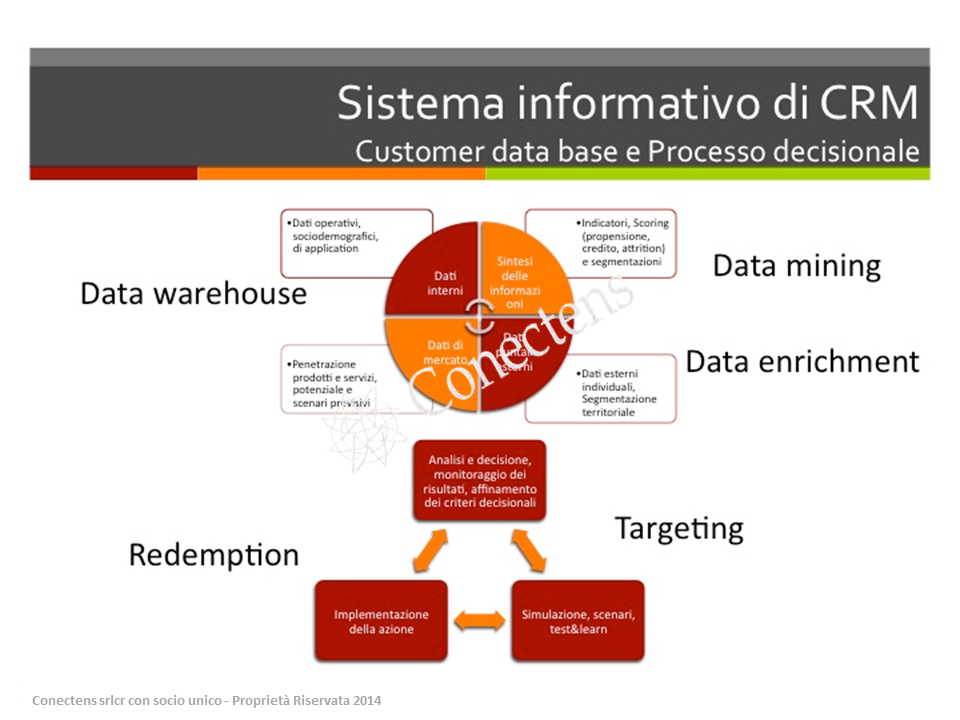
La messa in opera di una o più azioni test – su un target ristretto – consente di misurare l’impatto delle diverse azioni di contatto e di scegliere quella con ritorno più alto al fine di implementarla su larga scala.
La raccolta successiva dei ritorni – a livello di singolo cliente coinvolto nella azione – permette di aumentare la dimensione degli insights disponibili sul dato cliente: la storicizzazione di questi elementi consente quindi di arricchire ancor di più la base di dati disponibili sui clienti ed utilizzabile in ogni fase del processo di customer management – per qualsiasi altra azione si voglia mettere in opera.
Conclusioni
La richiamata rinnovata centralità del cliente, la necessità di fidelizzazione in un momento di cambiamento di attese ed atteggiamenti dei clienti e l’utilizzo di nuove fonti innovative che possano consentire di esplodere il contenuto informativo disponibile sui clienti non impatta il quadro di riferimento presentato.
Le aziende che hanno costruito nel corso del tempo un’infrastruttura come quella descritta possono essere nelle condizioni di valutare rapidamente l’impatto della disponibilità di nuove fonti informative così come l’impatto di un approccio diverso dei clienti (minore retention, processi di attrition più rapidi, diminuzione numero prodotti e relazioni, …) identificandone in anticipo bacino e segmento di provenienza e quindi anche le contromisure da adottare per contrastare il fenomeno.
Da un certo punto di vista le aziende che non hanno, ovvero hanno intrapreso parzialmente, la strada di sviluppo dei sistemi a supporto del customer management, possono paradossalmente beneficiare delle opportunità offerte da un terreno complessivamente più fertile in termini di disponibilità dei dati, aumentate efficienze informatiche, accresciute capacità analytics che consentono di colmare il gap ed anche di porsi all’avanguardia nel processo, puntando da subito sul patrimonio informativo più rilevante e differenziante, nonché di focalizzarsi sugli aspetti prioritari per accrescere la fidelizzazione del cliente e la capacità di retention.
Luciano Bruccola, Conectens. Proprietà riservata (2014)
[i] vedi Ernst & Young, The customer takes control – Global Consumer Banking Survey 2012
[ii] Bain & Company, Customer loyalty in retail banking Global edition 2012
[iii] vedi McKinsey Global Insitute, Big data: The next frontier for innovation, competition, and productivity 2011 e IBM Institute for Business Value in collaboration with Saïd Business School at the University of Oxford, Analytics: The real-world use of big data – How innovative enterprises extract value from uncertain data 2012